
本ページは広告が含まれています。気になる広告をクリック頂けますと、サーバ運営費になります(^^
最低限必要なシステム
以下のパッケージを利用して、簡単に生成AIを実行してみます。
PDFを学習資料として読み込み、書いてある内容から質問に答え、その出典を明らかにするというものです。
1.Ollama
- 役割:ローカルで動作する大規模言語モデル(LLM)サーバー。
- 特徴:
- PC上で軽量にモデルを実行できる(GPU不要でも可)。
- API経由でLangChainなどから呼び出し可能。
- 用途:テキスト生成、要約、質問応答など。
2. LangChain
- 役割:LLMを使ったアプリケーションを構築するためのフレームワーク。
- 特徴:
- LLMと外部ツール(DB、API、ファイル)をつなぐ。
- チェーン(処理の流れ)やエージェントを簡単に作れる。
- 用途:RAG(検索+生成)、チャットボット、ワークフロー自動化。
3. ChromaDB
用途:RAGで「質問に関連する文書を探す」部分を担当。
役割:ベクトルデータベース(Embeddingを保存・検索)。
特徴:
テキストやPDFをEmbeddingに変換して保存。
類似検索(semantic search)で関連情報を高速に取得。
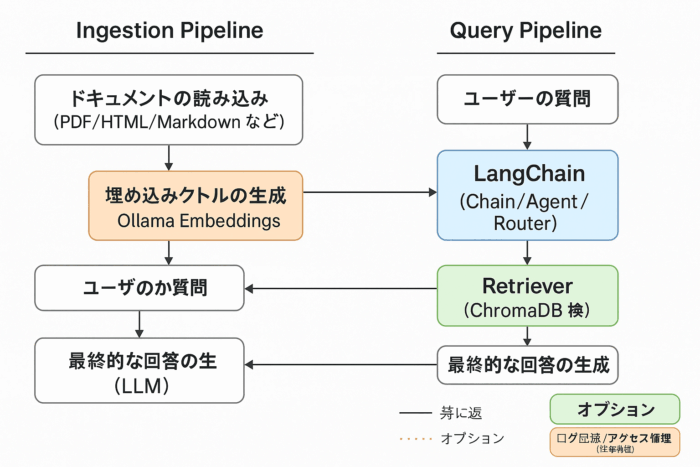
構築する全体像
RAGって何なのよ
大規模言語モデル(LLM)などの生成AIが、より正確で信頼性の高い回答を生成するために、外部の情報源から関連データを検索し、その情報を基に回答を生成する技術のことです。
全体像(RAGの流れ)
ChromaDB → 質問に関連する文書を検索してLLMに渡す
Ollama → LLMでテキスト生成
LangChain → LLMとChromaDBをつなぎ、質問応答のロジックを構築
試験環境
Lenovo Thinkpad Ryzen 5モデルで構築してみました。構築はとっても簡単です。とりあえずテストで動く事が目的ですが、かなり遅いです。
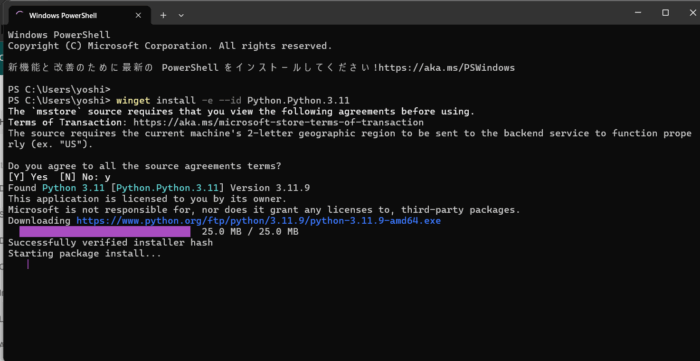
Python 導入
Python導入
winget install -e –id Python.Python.3.11
Ollma導入
winget install -e --id Ollama.Ollamaこの前入れたからすでに入ってた
> winget install -e --id Ollama.Ollama
Found an existing package already installed. Trying to upgrade the installed package...
No available upgrade found.
No newer package versions are available from the configured sources.文字化け対策
chcp 65001
# Ollama サービス起動(初回のみ、通常は自動起動)
ollama serve
# モデル取得
ollama pull llama3:8b-instruct-q4_K_M
ollama pull phi3:mini-4k # 予備(軽量)
ollama pull nomic-embed-text
プロジェクト作成 & ライブラリ導入
# 作業フォルダ
mkdir C:\rag-notice
cd C:\rag-notice
# いま開いている PowerShell のみ有効(管理者権限不要)
Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass -Force
# 仮想環境(推奨)
python -m venv .venv
.\.venv\Scripts\Activate.ps1
# ライブラリ
python -m pip install --upgrade pip
pip install langchain==0.2.* chromadb==0.5.* pypdf tqdm
pip install langchain-community
# LangChain から Ollama を呼ぶためのクライアント
pip install ollama
PDFを入れる
C:\rag-notice\pdfs\ ← このフォルダを作り、通達PDFをすべて入れるスクリプト
rag_pdf.py を作成して以下を保存
import os
import shutil
import argparse
from pathlib import Path
from tqdm import tqdm
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_ollama import OllamaEmbeddings
from langchain_community.llms import Ollama
from langchain.chains import RetrievalQA
def build_vector_db(pdf_dir: Path, db_dir: Path, embed_model: str, chunk_size=1000, chunk_overlap=200):
pdf_files = sorted([p for p in pdf_dir.glob("*.pdf") if p.is_file()])
if not pdf_files:
raise FileNotFoundError(f"PDF が見つかりません: {pdf_dir}")
print(f"[INDEX] PDF {len(pdf_files)}件を読み込み中…")
docs = []
for pdf in tqdm(pdf_files):
loader = PyPDFLoader(str(pdf))
docs.extend(loader.load())
splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
chunks = splitter.split_documents(docs)
print(f"[INDEX] チャンク数: {len(chunks)} (chunk_size={chunk_size}, overlap={chunk_overlap})")
embeddings = OllamaEmbeddings(model=embed_model)
# 既存DBがある場合は消して再構築(--rebuild 指定時)
if db_dir.exists():
shutil.rmtree(db_dir)
db = Chroma.from_documents(documents=chunks, embedding=embeddings, persist_directory=str(db_dir))
print("[INDEX] ベクトルDBを保存しました:", db_dir)
def load_vector_db(db_dir: Path, embed_model: str):
embeddings = OllamaEmbeddings(model=embed_model)
db = Chroma(persist_directory=str(db_dir), embedding_function=embeddings)
return db
def interactive_qa(db, gen_model: str, k: int = 3, language_hint: str = "日本語で、根拠を踏まえて簡潔に答えてください。"):
retriever = db.as_retriever(search_kwargs={"k": k})
llm = Ollama(model=gen_model)
# 検索結果(ソース)を一緒に返す
qa = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True,
chain_type_kwargs={
"prompt": None # 既定プロンプトでOK(日本語ヒントは query に付加)
},
)
print("\n=== 質問モード(終了: exit)===")
while True:
q = input("\n質問 > ").strip()
if q.lower() == "exit":
break
query = f"{q}\n\n{language_hint}\n以降の回答は必ず日本語で。"
result = qa({"query": query})
print("\n--- 回答 ---")
print(result["result"])
print("\n--- 出典 ---")
shown = set()
for doc in result["source_documents"]:
src = f"{Path(doc.metadata.get('source', 'unknown')).name} (p.{doc.metadata.get('page', 'N/A')})"
if src not in shown:
print("・", src)
shown.add(src)
def main():
parser = argparse.ArgumentParser(description="通達PDF向け RAG(出典表示つき)")
parser.add_argument("--pdf-dir", default="pdfs", help="PDF フォルダ")
parser.add_argument("--db-dir", default="db", help="ベクトルDB保存先")
parser.add_argument("--gen-model", default="llama3:8b-instruct-q4_K_M", help="生成モデル(Ollama)")
parser.add_argument("--embed-model", default="nomic-embed-text", help="埋め込みモデル(Ollama)")
parser.add_argument("--rebuild", action="store_true", help="ベクトルDBを作り直す")
parser.add_argument("--k", type=int, default=3, help="検索上位件数")
parser.add_argument("--chunk-size", type=int, default=1000)
parser.add_argument("--chunk-overlap", type=int, default=200)
args = parser.parse_args()
pdf_dir = Path(args.pdf_dir)
db_dir = Path(args.db_dir)
if args.rebuild or not db_dir.exists():
build_vector_db(pdf_dir, db_dir, args.embed_model, args.chunk_size, args.chunk_overlap)
db = load_vector_db(db_dir, args.embed_model)
interactive_qa(db, args.gen_model, k=args.k)
if __name__ == "__main__":
main()実行
cd C:\rag-notice
#実行ポリシーを変更
Set-ExecutionPolicy RemoteSigned
.\.venv\Scripts\Activate.ps1
# 初回はインデックス作成
python .\rag_pdf.py --rebuild
# 以降は通常起動(PDFを追加したら再度 --rebuild)
python .\rag_pdf.py
実際動かしてみた
(.venv) PS C:\rag-notice\.venv\Scripts> python .\rag_pdf.py --rebuild --pdf-dir "C:\rag-notice\pdfs"
[INDEX] PDF 28件を読み込み中…
100%|██████████████████████████████████████████████████████████████████████████████████| 28/28 [00:06<00:00, 4.38it/s]
[INDEX] チャンク数: 121 (chunk_size=1000, overlap=200)
C:\rag-notice\.venv\Scripts\rag_pdf.py:30: LangChainDeprecationWarning: The class `OllamaEmbeddings` was deprecated in LangChain 0.3.1 and will be removed in 1.0.0. An updated version of the class exists in the :class:`~langchain-ollama package and should be used instead. To use it run `pip install -U :class:`~langchain-ollama` and import as `from :class:`~langchain_ollama import OllamaEmbeddings``.
embeddings = OllamaEmbeddings(model=embed_model)langchain-community ではなく、langchain-ollama パッケージを使うように変更する必要があります。
pip install -U langchain-ollamaエラーが出たので修正
# PostHog を互換バージョンに落とす(必須)
(.venv) PS> pip install –upgrade –force-reinstall “posthog<6.0.0”
# 念のため ChromaDB も最新安定へ(0.5系のままでもOK)
(.venv) PS> pip install -U chromadb
# 反映確認
(.venv) PS> pip show posthog
LangChain 側の Ollama を新パッケージに移行(推奨)
pip install -U langchain-ollama
