
本ページは広告が含まれています。気になる広告をクリック頂けますと、サーバ運営費になります(^^
PDFの全文検索システムを作りたい
Fess PDF全文検索
色々と調べてみたら、FessというシステムでPDF全文検索ができると知りました。LINUXでも動くらしい。以前はCGI のNamazuを使って構築したことがありましたが、最近は更新もなく、こちらのFessの方がスタンダードっぽいです。
Fess公式サイト
公式サイトはこちらです。
[browser-shot url=”http://fess.codelibs.org/ja/articles/article-1.html” width=”600″ height=”450″ target=”_blank”]
インストールについて
例によって私はDebian使い。手元にサーバが無かったので、お年玉クーポン3万円を配布していたAltusを利用してUbuntuディストリビューションで構築してみます。
JDKのインストール
apt-get install default-jdk
apacheのインストール
apt-get install apache2
構築した後で分かりましたがapacheはFessの動作自体には必要ありません。80番でアクセスさせたい時に利用します。Fessデフォルトの起動ポート8080でアクセスさせる際には必要ないです。同じサーバで、webサイト公開したいのなら必要です。webサイトで公開しているhtml,txtその他PDFファイルなどをクロールして検索する事ができる。
Debがあったのでこちらは失敗
debファイルがあったので、こちらで構築しようとしましたが起動せず。なんでだろう。
Fess 11.4.5の取得(2017.12.18)
wget https://github.com/codelibs/fess/releases/download/fess-11.4.5/fess-11.4.5.deb
fessのインストール
# dpkg -i fess-11.4.5.deb Selecting previously unselected package fess. (Reading database ... 92510 files and directories currently installed.) Preparing to unpack fess-11.4.5.deb ... Creating fess group... OK Creating fess user... OK Unpacking fess (11.4.5) ... Setting up fess (11.4.5) ... Processing triggers for systemd (229-4ubuntu7) ... Processing triggers for ureadahead (0.100.0-19) ...
/usr/shar/fess/bin にインストールされる
# ls /usr/share/fess/bin/ fess fess.in.sh generate-thumbnail plugin.xml
起動しようとしたら起動しないので削除
dpkg -r fess (Reading database ... 100790 files and directories currently installed.) Removing fess (11.4.5) ... Stopping fess service... OK
うまくインストールできたとおもったのですが。
ZIPバージョンで構築
気を取り直してzipバージョンを取得
wget https://github.com/codelibs/fess/releases/download/fess-11.4.5/fess-11.4.5.zip
zipを解凍
unzip fess-11.4.5.zip
名前をfessに変更して配置
mv fess-11.4.5 /usr/share/fess
fess を実行
/usr/share/fess/bin# ./fess
無事起動するようになりました。
注意情報
fessは、初期動作が遅くて。ホームページが表示されるまでに5分以上かかる。あまりにも遅くて、「あれサーバ起動しているはずなのに動かないってなる。」根気強く待つと、安定稼働始める。
fess01.jpg
管理画面へのログイン
http://ホスト名:8080
初期パスワードは下記の通り
ユーザ名:admin
パスワード:admin
インデックス作成から検索まで
この手順に従って行けばインデックスが作成され検索できるようになるはず。私は今回web検索でヒットするように設定したが、なかなか思うような結果が出ずに苦労した。詳細は次の項目で。
fess05.jpg
PDFファイルがクロールされないトラブル
クロールとは
クローラーというボットが、情報を集める行為。Googleのウェブクローラーは[Googlebot]という名称。巡回ロボット。クローラーが情報を収集する行為をクロールといい、fessでもcrawlerという名称でクロールの設定ができる。webサイトの情報を集める事。クローラーはリンクをたどってクロールされるので、リンクがなければクロールされない。
注意1 そもそもPDF内のテキストは大丈夫か?
OCRで読み取りを行った際に、古いアプリや、書籍自体も古く紙が劣化していると、スキャンデータ自体が文字化けしている事があります。この状態ではいくらクロールかけても検索結果は出てきません。一度、PDFの文字列をコピーしてテキストなどに貼り付けてみてください。これでちゃんと読める状態ならクロールをかけて検索できるようになります。fessの検索機能は画像検索で文字列に変換してなんて事はできないので、PDF東名テキストがしっかりあるかどうかは大きなポイントです。
注意2 クロール対象のファイルサイズが大きいと、インデックスされない。

デフォルトでは HTML ファイルは 2.5M バイト、それ以外は 10M バイトまで処理します。 扱うファイルサイズを変更したい場合は app/WEB-INF/classes/crawler/contentlength.xml を編集します。
10485760
“text/html”
2621440
編集した後はfess本体を再起動する必要があります。私は、まだこの時点で起動スクリプトrc2.d作成していませんので、プロセスを探して直接Killしました。
注意3 PDF内の文字がクロールされない
fess-crawler.logに
06:52:34,987 [Crawler-20171220065154-1-1-pdf] WARN Using fallback font LiberationSans for CID-keyed TrueType font MSGothic
2017-12-20
と表示され、PDF内の文字がクロールされない場合、こちらを参考にしました。
[browser-shot url=”https://github.com/codelibs/fess/issues/1157″ width=”600″ height=”450″ target=”_blank”]
にて、設定パラメータに
crawler.ignore.robots.txt=false
とする事でクロールされるようになった。
注意3 ファイルサイズが大きすぎる
10:22:37,115 [Crawler-20171220094722-1-1] ERROR Crawling Exception at http://fess.hanako.or.jp/hanako1992.pdf
java.lang.OutOfMemoryError: Java heap space
contentlength.xmlの扱うファイルサイズを大きくしても、JAVAがヒープスペースを確保できなくてOutOfMemoryErrorが出てしまう事があります。仕方がないので、サーバのメモリ容量を上げて対応です。ALTUSのクラウドサーバを試験利用していて、こちらをm1.smallから、m1.largeへ変更。
m1.smallは1コアvCPU / 2GBメモリ
m1.largeは2コアvCPU / 8GBメモリ
うーんお金かかる。とりあえず、Indexを作る時だけlargeにしようかな。
注意4 クローラ側のヒープメモリー最大値の変更

FESS_MIN_MEM=512m
だったものを
FESS_MIN_MEM=2g
に変更しました。MAX_MEM = 2gなんで、勝手に可変してくれるんじゃないかと思うのですが、私の場合はこれで正常クロールされるようになりました。
/usr/share/fess/bin# vi fess.in.sh
#!/bin/sh
FESS_CLASSPATH=$FESS_HOME/lib/classes
if [ "x$FESS_MIN_MEM" = "x" ]; then
FESS_MIN_MEM=2g
fi
if [ "x$FESS_MAX_MEM" = "x" ]; then
FESS_MAX_MEM=2g
設定変更後は再起動が必要です。
注意5 ウエブファイルをクロールするなら、リンク必須
ウェブファイルをクロールする設定にする場合は、アクセスできるHTMLからリンクが張られている必要があります。指定したディレクトリを自動的にクロールしてくれるわけではありません。リンクが必要です。リンク先をどんどんクロールしてくれます。
クロールができているか確認
クロール対象の登録
ウェブクロールの設定を行います。
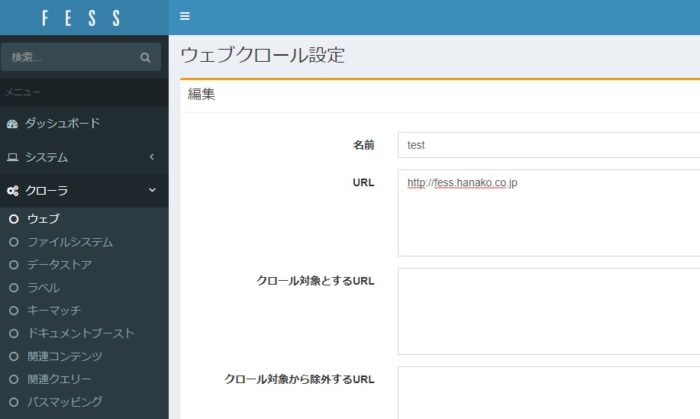
クロールの開始
システム⇒スケジューラ⇒Default Crawler
を、いますぐ開始します。
fess05.jpg
クロール状態の確認
クロールが完了しているか確認します。
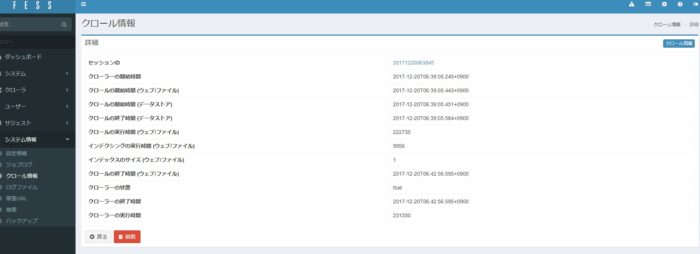
fess04.jpg
webでクロールする場合は、検索対象からさらにリンクが張られている事を確認します。リンクがないと、検索されません。
クロール設定で、クロール対象とするURLを設定するのはいいですが、URLで指定した以外はクロールされなくなってしまうため、
http://ホスト名/.*
の.*を忘れないようにします。これを忘れると、http://ホスト名/しかクロールしてくれない事になり、index.htmlなどデフォルトで表示できるようにしているwebサイトしかクロールされなくなります。
補足 Search Everything
PDF全文検索システムを、WordPressで簡単に作成できないかと探してみたところ、Search Everything というプラグインがある事が分かりました。チャレンジしてみたのですが、思った通りの結果は出ませんでした。また、インデックス作成タイプでもないので、もし動いたとしても処理速度は遅いだろうと思います。
一応完了できなかったのですが、下記はメモで残しておきます。
WordPressで、全文検索サイトを作ってみようとチャレンジしてみました。Search Everything
投稿や、記事だけでなく、PDFの全文検索サイトを作成してみます。

WordPressのデフォルト検索機能を向上させます。ページ、抜粋、添付ファイル、下書き、コメント、タグ、カスタムフィールド(メタデータ)を検索するように設定し、独自の検索ハイライトスタイルを指定することができます。
検索速度も気になるところです。
プラグイン Search Everythingのインストール
Serch Everythingプラグインを探し、インストール有効化します。
Serch Everythingオプション変更
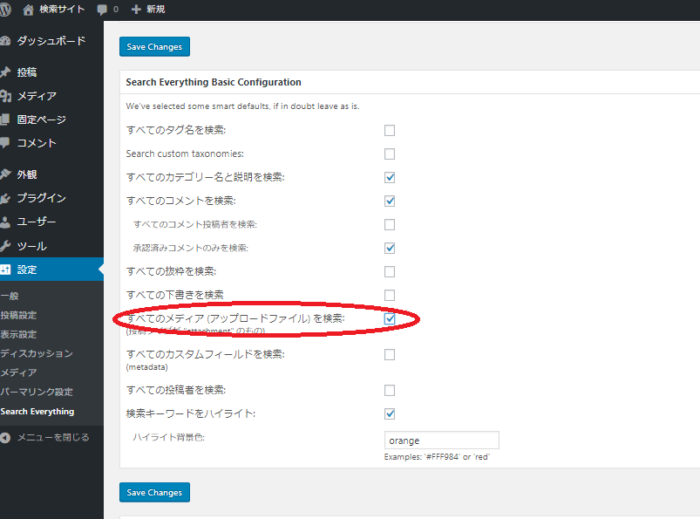
everysearch01.png
すべてのメディア (アップロードファイル) を検索: にチェックを入れます。
これで検索されるはずなのですが、ファイルサイズが大きすぎるのか検索できませんでした。

